OMSI Data Format¶
The following discusses the specification and use of OMSI mass spectrometry imaging data files.
Data Layout¶
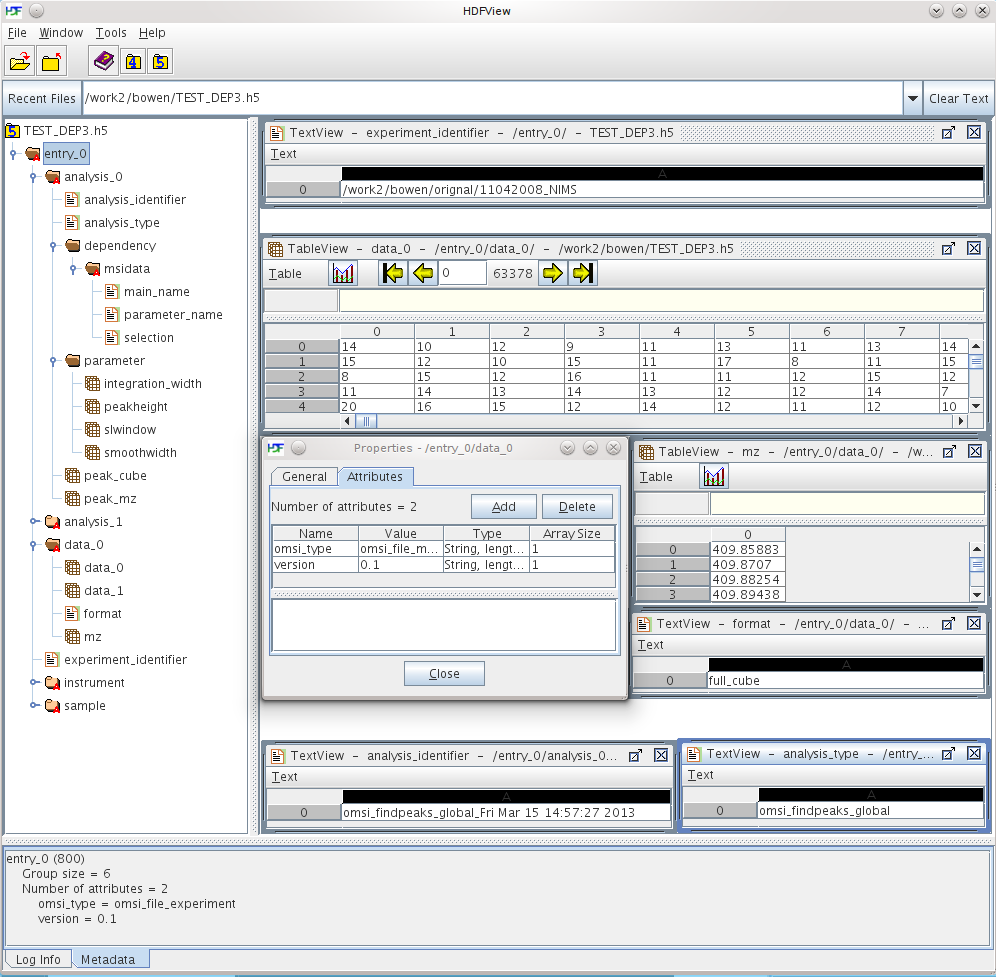
Illustration of an example HDF5 file using the OpenMSI data format.
Experiment Information
/entry_#(HDF5 group) : Each /entry# groups stores data for a single imaging experiment. Data from multiple related experiments may be stored in different /entry_# groups within the same file. To link data from related experiments that are stored in separate HDF5 files, one could create a master-file in which the /entry_# are softlinks to the corresponding groups in the external HDF5 files/entry_#/experiment_identifier(String dataset) : For each experiment a user-defined identifier name —which should be unique— is stored. This can be used to search for a particular experiment based on its name.
MSI Data
/entry_#/data_#(HDF5 dataset) : Multiple original images may be stored for each imaging experiment. The OMSI format manages the data associated with each dataset in a seperate group. For a standard MSI dataset this group contains the following datasets:/entry_#/data_#/data_#(3D dataset) : Each data group may contain multiple copies of the same data. This is to allow for optimziations of the data layout for different selective read operations. This is important to enable fast data access to spectra and images via the web. By default the omsi format uses 3D arrays to store the spectral imaging data because:- This allows the use of chunking in HDF5 to optimize data access for slicing operations in all dimensions. 1D and 2D layout allow for optimization only for a limited set of selection operations.
- When using, e.g., a 1D data array to store the data, one would also need to store the resolution and order of the different dimensions to make sure that one can interpreted and read the data correctly.
/entry_#/data_#/format(String dataset) : Simple string dataset describing the internal layout type of the dataset. While the most common data layout is to store the data in a single 3D array, other data layouts are supported as well, e.g., to enable more efficient storage for sparse MSI datasets./entry_#/data_#/mz(1D dataset) : The m/z values associated with the data.
Instrument Information
/entry_#/instrument(HDF5 group) : For each experiment a group with additional data about the instrument is stored. The example shown above defines a name for the instrument but we could define a larger list of optional instrument information that we would like to store here. The CXIDB format allows multiple instruments for each experiment. To assign data uniquely to an instrument the data is stored in the corresponding instrument group. However, to ease access to the data, CXIDB defines soft-links to the data in the /entry_# group for the experiment as well. Allowing multiple instruments for a single experiment makes the format very complicated and is unnecceasry in most cases. In the OMSI format defined here, one can still store data from related experiments in a single file, simply by creating separateentry_# group./entry_#/instrument/name(String dataset) : The name of instrument used/entry_#/instrument/mz(1D dataset) : The mz data of the instrument
Sample Information
/entry_#/sample(HDF5 group) : For each experiment a group with additional data about the sample used in the experiment is stored. The example shown below only defines a name for the sample but we could define a larger list of optional instrument information that we would like to store here. The proposed format here makes a similar simplification compared to the CXIDB format as in the case of the instrument. For each experiment —represented by a/entry_# group— only a single sample may by used. Data from related samples may be stored in the proposed format in separate/entry_#groups representing different experiments./entry_#/sample/name(String dataset) : Name of the sample imaged.
Data Analysis Results
/entry_#/analysis_#(HDF5 group) : Multiple derived analysis results may be stored in the proposed format in analysis_# groups associated with the experiment they were created from. Similar to the experiment a user-defined analysis-identifier string should be given to each analysis to allow searches for analysis results by name. Which data needs to be stored for an analysis will depend on the analysis. The omsi python API specifies some base classes to ease integration of analysis algorithms with the API and the HDF5 data format. Further formalizations may be specified to ease support of specific types of analysis results —e.g., clustering results— via the OpenMSI web-interface./entry_#/analysis_#/analysis_identifier(String dataset) : For each analysis a user-defined identifier name —which should be unique— is stored. This can be used to search for a particular experiment based on its name./entry_#/analysis_#/analysis_type(String dataset) : String describing the type of analysis. This should be high-level category, e.g., peak_finding_local, peak_finding_global, clustering etc. We will define a set of these categories that should be used. Having high-level categories for different algorithms that store their data in the same fashion will help later on with analyzing and visualizing the results from different algorithms that essentially produce the same output./entry_#/analysis_#/...(Arbitrary HDF5 dataset) : In the example shown in Illustration of an example HDF5 file using the OpenMSI data format. above, we have an example /entry_0/analysis_0/peakcube. The name for the output datasets from the analysis is currently not restricted. A set of name convention will however be defined by the omsi_analysis associated with the indicated analysis_type to ensure that the data can be handled gracefully. Otherwise, if an unkown analysis type is given then all datasets in the /entry_#/analysis_#/ group that are not part of the standard are assumed to be analysis datasets./entry_#/analysis_#/parameter(HDF5 Group) : Group containing addional datasets with input parameters of the analysis/entry_#/analysis_#/parameter/...(Arbitrary HDF5 datasets) : Datasets defining input parameters of the analysis
/entry_#/analysis_#/dependency(HDF5 Group) : Group containing additional datasets specifying dependnecies of the analysis./entry_#/analysis_#/dependency/...(HDF5 Group) : Each dependency is defined in a seperate group containting the following required datasets/entry_#/analysis_#/dependency/.../main_name(String dataset) : Path to the HDF5 object the analysis depends on./entry_#/analysis_#/dependency/.../parameter_name(String dataset) : Name of the analysis parameter that has the dependency./entry_#/analysis_#/dependency/.../selection(String dataset) : Optional Numpy selection string, indicating the subset of the data used.
/entry_#/analysis_#/runinfo/(HDF5 Group) : Group containing all runtime information data, e.g., start, stop and execution times, system and OS metadata etc.
Attributes
HDF5 attributes are used by the OMSI file format only to store format related information but not to store any data. Currently the following attributes are associated with the different high level groups:
omsi_type(String) : Attribute indicating the omsi_file API object to be used to manage the given groupt. If the attribute is not present then the API decides which API object to use base on the name conventions described above.version(String) : Attribute indicating the version of the API class that should be used to represent this group.
Accessing OMSI data files¶
The omsi.dataformat.omsi_file module provides a convenient python-based API for reading and writing OMSI data files. The class also provides a convenient function for generating a XML-format XMDF header for the OMSI HDF5 file. Using the XDMF header file, the HDF5 data can be loaded in VisIt using VisIt’s XDMF file reader. OMSI data files are valid HDF5 data files and can be accessed via the standard HDF5 libraries.
C/C++:
- More information about HDF5 can be found here: http://www.hdfgroup.org/HDF5/
Python:
- H5Py is a python interface to the HDF5 library. More detailed information can be found here: http://h5py.alfven.org/docs-2.0/
MATLAB:
MATLAB provides both high-level and low-level access functions to HDF5. For more details see http://www.mathworks.com/help/techdoc/ref/hdf5.html
Simple example usin the high-level API:
file='~/Data/Imaging/DoubleV.hdf5' h5disp(file) mz=h5read(file,'/entry_0/instrument/mz'); [m mx]=min(abs(mz-746.22)) tic y=h5read(file,'/entry_0/data_0',[mx 1 1],[1 250 160]); toc imagesc(squeeze(y)) axis equal axis tight
Simple example using the low-level API:
file='~/Data/Imaging/DoubleV.hdf5' plist = 'H5P_DEFAULT'; fid = H5F.open(file); gid = H5G.open(fid,'/entry_0'); dset_id = H5D.open(fid,'/entry_0/data_0'); dims = [160 250 1]; offset = [0 0 mx] block = dims; mem_space_id = H5S.create_simple(3,dims,[]); file_space_id = H5D.get_space(dset_id); H5S.select_hyperslab(file_space_id,'H5S_SELECT_SET',offset,[],[],block); tic data = H5D.read(dset_id,'H5ML_DEFAULT',mem_space_id,file_space_id,plist); toc H5D.close(dset_id); H5F.close(fid); data=squeeze(data); imagesc(data) axis equal axis tight
Using HDF5 at NERSC
Overview of python at NERSC: http://www.nersc.gov/users/software/development-tools/python-tools/
HDF5 modules are installed on most machines at NERSC:
module load hdf5 module load python python >>> import h5py >>> import numpy
Convert Mass Spectrometry Imaging Data to OMSI (HDF5) format¶
See section Converting Files at NERSC and Making them Accessible for details.
omsi.tools.convertToOMSI: This python script, which is available via the OMSI software toolkit, provides functionality for converting img files to HDF5. The script takes a single or multiple img files as input and writes them to a single HDF5 file. The data of each img file is stored in a separate/entry_#/data_#object. The script also supports execution of a number of different analysis, such as, peak finding or nmf, directly during the data conversion. For up-to-date information about the usage of the script seepython imgToHDF5 --help. A summary of the main command-line options of the tool are available below.omsi.dataformat.omsi_file: Module containing a set of python class for reading and writing HDF5 data files for the proposed OMSI HDF5 data layout.omsi.dataformat.img_file: Simple python class for reading img data files.omsi.dataformat.bruckerflex_file: Simple python class for reading bruckerflex files.